Scraping, Cleaning & Loading Pipeline
Automated collection of 8,000+ records from 9 PSL seasons (2016–2024)
Project Summary
This project showcases an end-to-end ETL (Extract, Transform, Load) pipeline using dynamic web scraping with Selenium and Python. It collects match-level player stats from ESPNcricinfo, cleans the data using Pandas, and stores the final structured records in AWS RDS for further analysis. Real-world data engineering and automation are demonstrated throughout.
Sample Results
Web to Table: Screenshots show scraped pages from ESPNcricinfo and the final cleaned datasets.
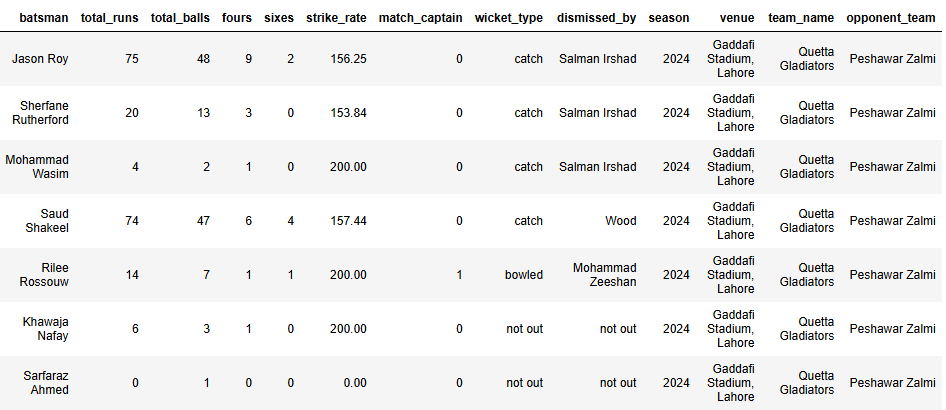
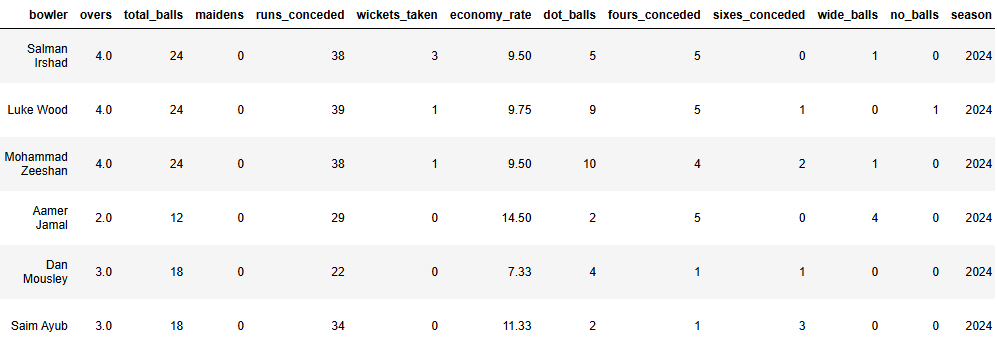
View Complete Dataset on Kaggle
Pipeline Architecture
Overview: A multi-threaded scraper automates Microsoft Edge to navigate and extract dynamic HTML from PSL match pages. Using concurrent threading, multiple matches are scraped in parallel. BeautifulSoup parses the HTML, Pandas cleans the data, and SQLAlchemy loads it into AWS RDS Aurora securely.
1. Extraction
- Selenium
- ThreadPoolExecutor
- BeautifulSoup
2. Transformation
- Pandas DataFrames
- CSV Storage
3. Loading
- SQLAlchemy ORM
- AWS RDS MySQL
Key Achievements
| Metric | Result | Impact |
|---|---|---|
| Collection Speed | < 15 minutes | 75% faster than sequential |
| Data Validity | 99% valid records | Reliable analytics base |
| Storage | AWS RDS | Cloud-ready complete data (2016-2024) |
What I Learned: Hands-on experience with Selenium, concurrency, data cleaning, and cloud databases. Learned how to optimize scraping at scale and parse inconsistent HTML structures.
Applications
- Data dashboards for player trends
- ML models for performance prediction
- EDA and cricket analytics
- Fantasy league tools and blog content